## Docker搭建flink+kafka(二)快捷脚本批量执行SQL作业
- 本人使用阿里云实时计算Flink全托管版,使用SQL编写作业,不需要复杂的开发环境,,为了方便快捷执行,准备了如下环境快速开发SQL作业
- IDEAJ中创建项目
- pom.xml
- [](https://static.adong.wiki/static/images/md/2021010201.png)
``` xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>adong.wiki</groupId>
<artifactId>flink-sqlsubmit</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<flink.version>1.11.2</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<rocketmq.version>4.8.0</rocketmq.version>
<commons-lang.version>2.5</commons-lang.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
```
- 准备好Java脚本后。IDEAJ中打包jar包
- 源码参考 [https://gitee.com/adongge/flink](https://gitee.com/adongge/flink)
- 编写sql-submit.sh
``` Bash
#!/bin/bash
f0="/home/dev/sql/source.sql"
f1="/home/dev/sql/sink.sql"
f2="/home/dev/sql/job.sql"
sql_file="$f0,$f1,$f2"
AD_JAR=/home/dev/flink-sqlsubmit-1.0-SNAPSHOT.jar
/home/flink/bin/flink run -p 1 -c local.sqlsubmit.SqlSubmit $AD_JAR -f $sql_file
# docker exec -it adflink /bin/bash -c '/home/dev/sql-submit.sh'
# docker exec -it adflink /bin/bash -c '/home/flink/bin/flink list'
```
- 在sql目录中编写sql作业内容
``` SQL
-- 源表 /home/dev/sql/source.sql
create table test_source (
device_number STRING
) with (
'connector' = 'kafka',
'topic' = 'testtopic',
'properties.bootstrap.servers' = 'adkafka.com:9092',
'properties.group.id' = 'testtopic_source',
'format' = 'csv',
'csv.field-delimiter' = '#',
'csv.ignore-parse-errors' = 'true',
'scan.startup.mode' = 'earliest-offset'
);
-- 结果表 /home/dev/sql/sink.sql
create table test_sink (
device_number STRING
) with (
'scan.fetch-size' = '1',
'connector' = 'jdbc',
'password' = '123456',
'username' = 'root',
'table-name' = 'test',
'url' = 'jdbc:mysql://172.10.0.1:3308/kpr_db?rewriteBatchedStatements=true&serverTimezone=GMT%2B8'
);
-- 作业 /home/dev/sql/job.sql
INSERT INTO test_sink(device_number)
SELECT device_number FROM test_source
```
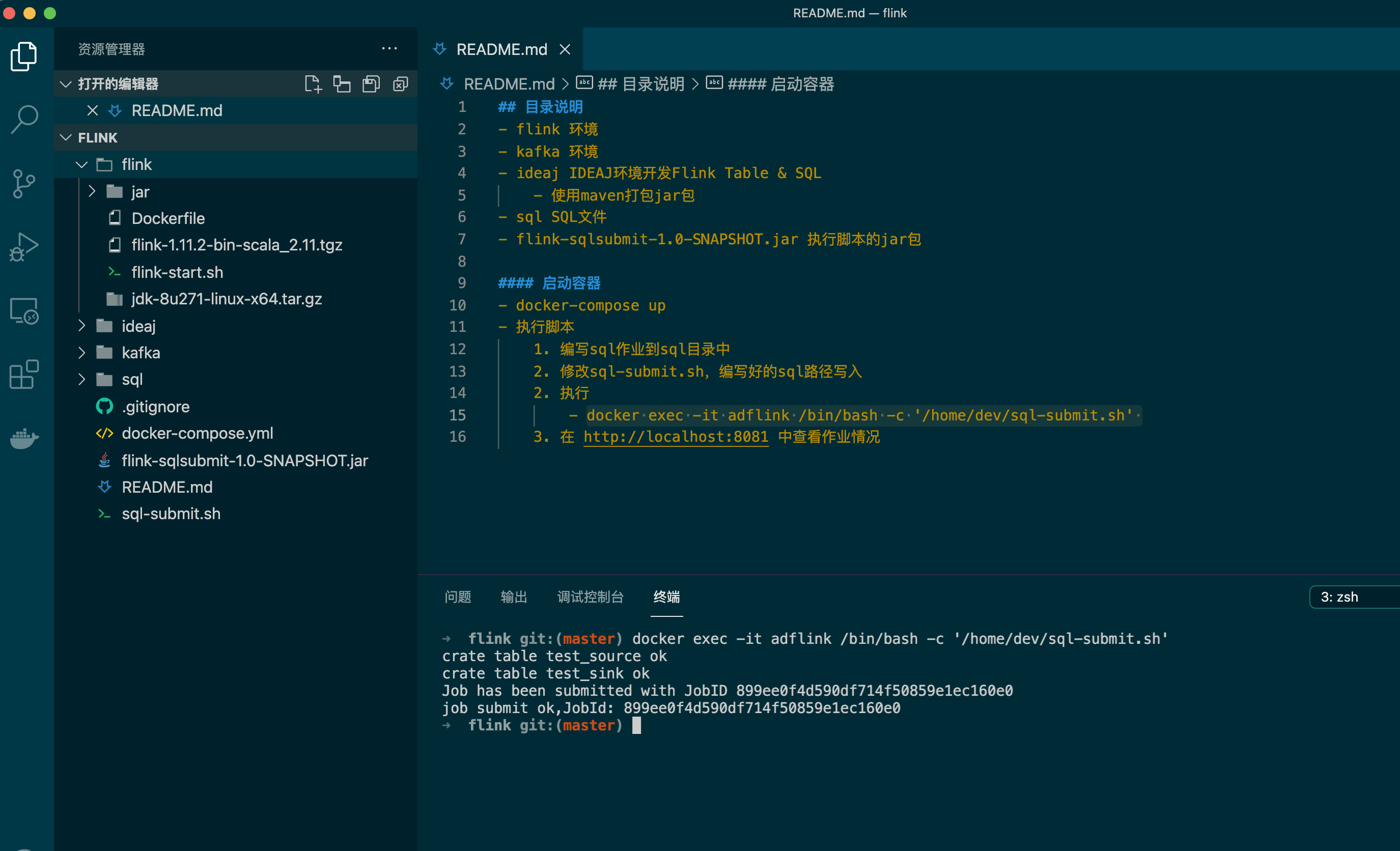
- 执行 docker exec -it adflink /bin/bash -c '/home/dev/sql-submit.sh'
- [](https://static.adong.wiki/static/images/md/2021010202.png)
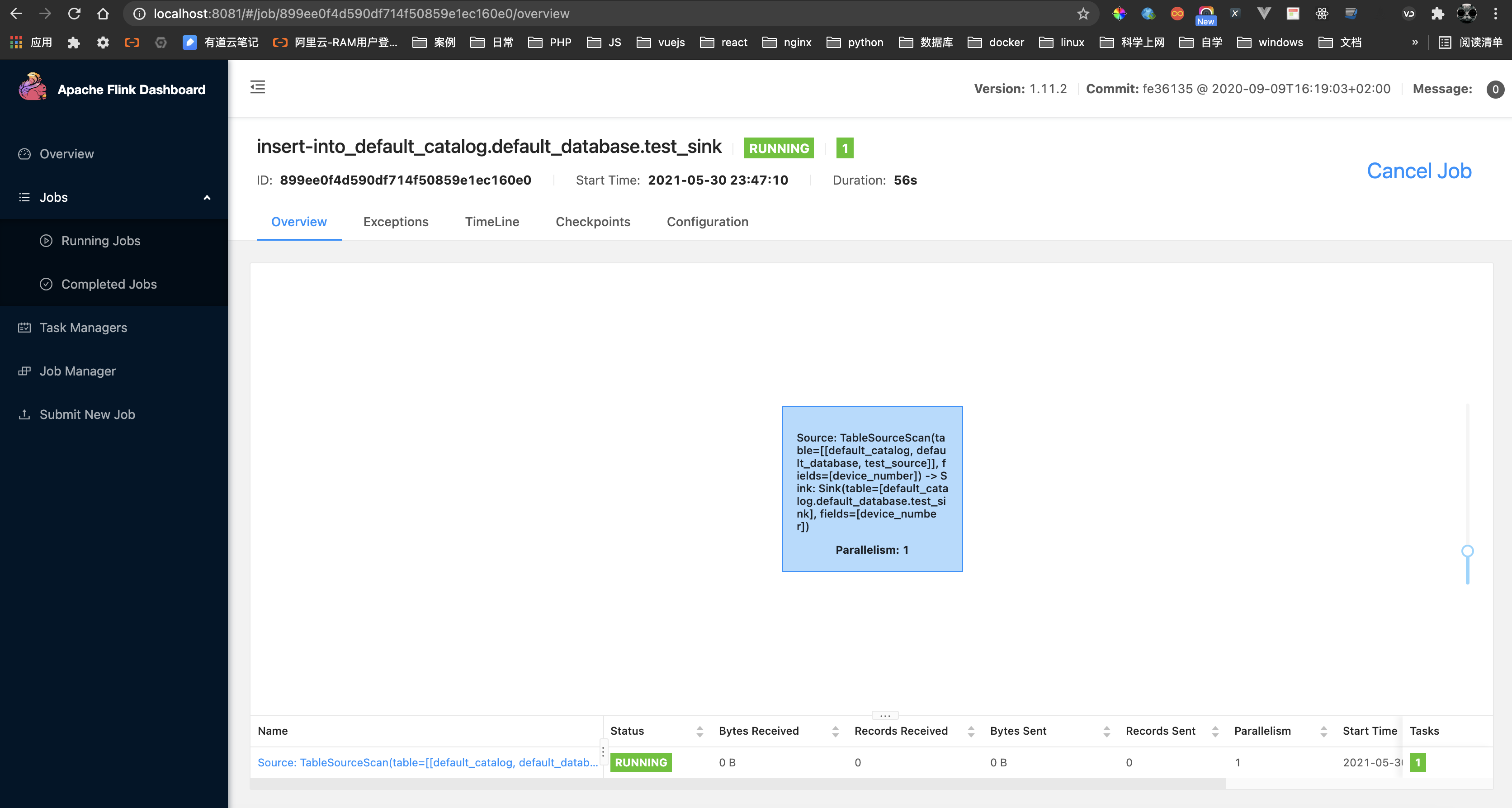
- 在 http://localhost:8081 中查看作业提交情况
- [](https://static.adong.wiki/static/images/md/2021010203.png)
- 本地开发测试搞定,就可以专注SQL作业,无需编写java代码,方便快捷本地测试开发